Jenkins website management
As an attempt to learn more about how Jenkins works, do my own experimenting and generally expand my knowledge I decided to go down the complicated path of using Jenkins to deploy my website.
The website itself is statically hosted on an S3 bucket using a CloudFront frontend to deliver the content. Part of the content includes this blog, managed using Jekyll.
The basic process is as follows:
- Maintain a local copy of the website on my Macbook managed with git. I regard this as a trivial step these days.
- Use AWS Code Commit as a Git repository for the website. This requires us to set up an IAM user with CodeCommit access combined with an SSH key.
- Have Jenkins check out the website and do some work on the files in the repository. The Jenkins server is an Amazon EC2 instance (which I refer to as devserver).
- Copy the website from the Jenkins server to an S3 bucket.
Note: it would arguably make way more sense when doing this to use AWS CodeBuild and a Lambda function to deploy the code - but that would defeat the purpose of learning Jenkins, which was the major point of the excercise.
I assume for this setup you have already done the following:
- Set up and installed Jenkins on an AWS server.
Site setup
The idea behind the site on the local laptop is fairly straightforward. The site has a main home page in the root folder (at the time of writing this was a very basic index.html and error.html) as well as a subfolder containing a web page generated while doing the A Cloud Guru course “Create a Serverless Portfolio with AWS and React”. Additionally I have a blog subfolder contain a Jekyll based blog which will need to be processed before being uploaded to the webserver/S3 Bucket.
The build process is therefore:
- Create a build subfolder to hold the website.
- Copy all static files to the build folder, keeping the relative paths. Static files must be listed in a STATICFILES file which is held within the repository. All files in the root folder and all sub folders that can be copied accross directly should be listed in this file.
- Use Jekyll to generate the webpages required for the blog pages which are saved in the blog subfolder of the build server.
For now, it’s considered acceptable to have up to a five minute delay before the revised page is pushed out to the S3 bucket. We will configure to check the Code Commit repository every five minutes to see if there are changes, and run the build process if there are changes.
AWS Code Commit
I have an IAM group with the following policies (all standard AWS policies) attached:
- AWSCodeCommitFullAccess
- IAMSelfManageServiceSpecificCredentials
- IAMReadOnlyAccess
- IAMUserSSHKeys
I’ve attached this group to a web-dev user who also has full access permissions to the S3 bucket hosting the website.
To get the ssh key to add to your account, do the following:
su - jenkins ssh-keygen
Then go to the IAM console, select your user for code commit, and add the ssh key (the contents of the id_rsa.pub file in your jenkins account on the server) to the Security Credentials tab on the User page for your account.
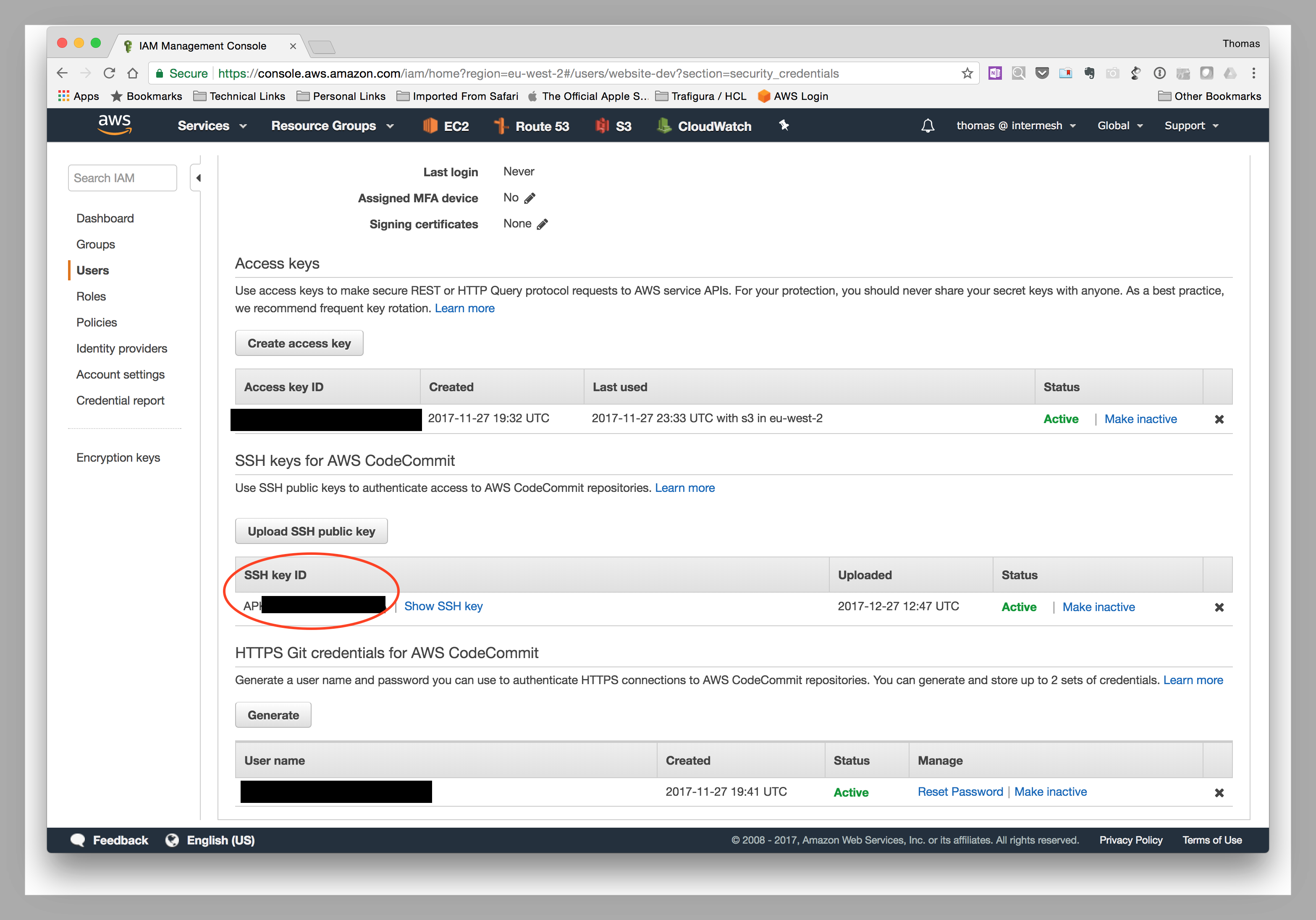
The console will allocate an SSH Key ID to the uploaded ssh key - you will need this to set up the build in Jenkins. Additionally, you should configure the ~jenkins/.ssh/config file as follows:
Host git-codecommit.*.amazonaws.com
User <SSH Key ID>
IdentityFile ~/.ssh/id_rsa
I would recommend logging into the jenkins account on the server and verifying you can check out the repository on the command line. In CodeCommit, go to the repository and click the connect button to get the git command to use to clone the repository. At this point, the Code Commit setup is completed.
Jenkins Server setup
The Jenkins server I am running has the following plugins installed:
- AWS CodeCommit Trigger Plugin
- Credentials Plugin
- Git client plugin
- Git plugin
- SSH Credentials Plugin
(There are more plugins installed, but these are the ones that to my inexperienced eye seem to be essential here).
There are two parts to setting up the server.
1. Install the credentials.
On the Jenkins homepage, click Credentials. Click Jenkins, then click “Global credentials (unrestricted)”. Click “Add Credentials”.
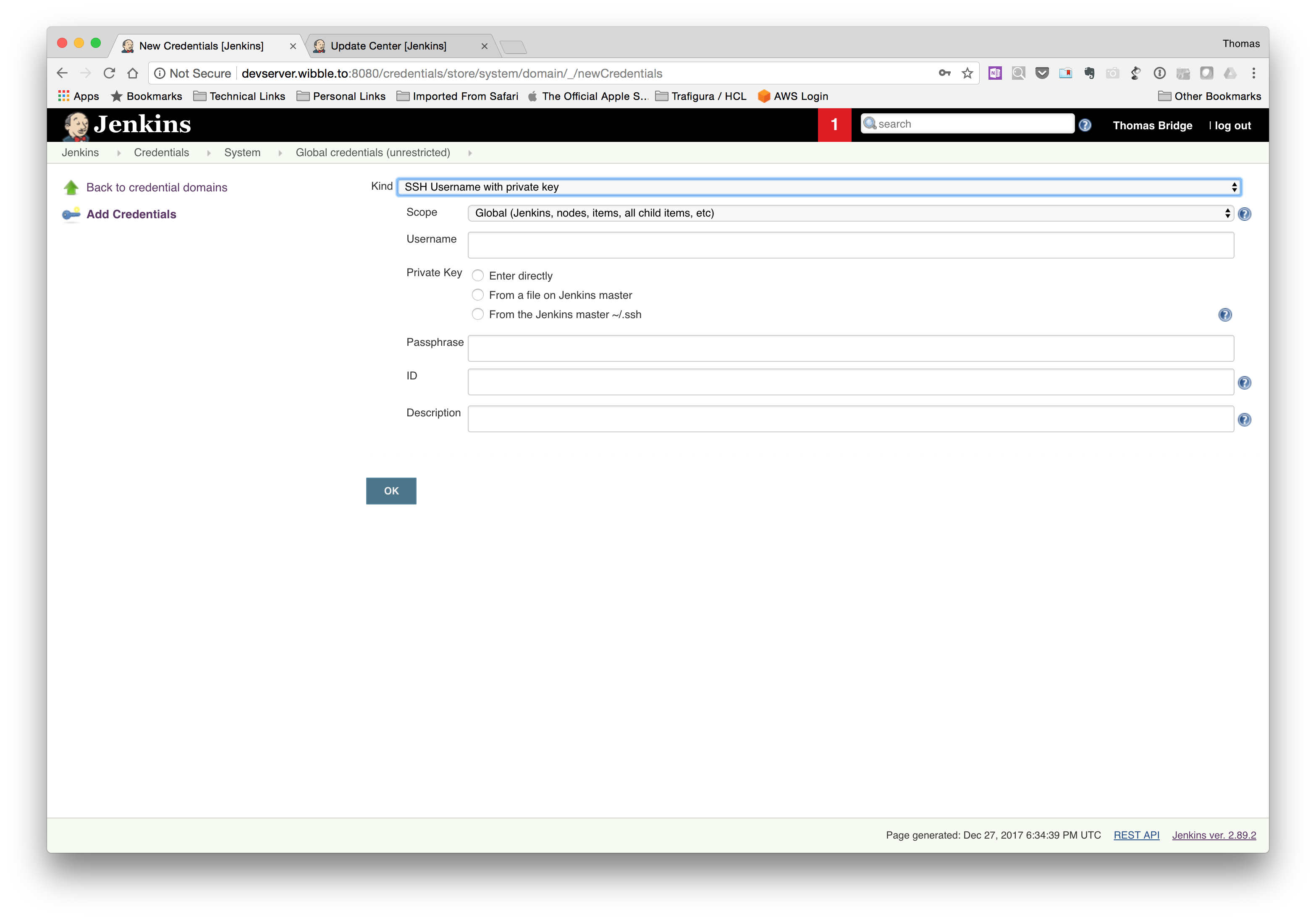
Fill the fields out as follows:
- Kind: “SSH Username with private key”
- Scope: “Global (Jenkins, nodes, items, all child items, etc)”
- Username: Use the AWS SSH Key ID identified in the previous section.
- Private Key: Select “From the Jenkins master ~/.ssh”
- Passphrase: (only if entered during the ssh key generation)
Click OK to save the credentials.
2. Configure the build process.
Create a Freestyle project and name it appropriately.
I used the following options.
- General
- Checked “Discard old builds”
- Source Code Management
- Select git
- In Repository, enter the ssh URL of the Code Commit repository.
- Credentials: select the AWS SSH Key ID in the drop down menu.
- Build triggers
- Select Poll SCM
- Set the timings as “H/05 * * * *”
In the next section we’ll discuss the build script to be created under Execute Script.
3. Build the website and then upload to the S3 bucket.
I used the following script to build the website and upload it to the S3 bucket.
BUILDDIR=$WORKSPACE/build
if [ -e $BUILDDIR ] && [ ! -d $BUILDDIR ]
then
echo $BUILDDIR exists, removing.
rm -rf $BUILDDIR
mkdir $BUILDDIR
fi
rsync -v --files-from=$WORKSPACE/STATICFILES $WORKSPACE $BUILDDIR
jekyll build -s $WORKSPACE/blog/ -d $BUILDDIR/blog/ --incremental
aws s3 sync $BUILDDIR s3://www.wibble.to/ --delete --acl public-read
Some explanatory notes as to the logic in the script:
- Every time Jenkins runs the build process, it checks out the latest copy of the git repository into the root of the workspace.
- The build folder is in the Workspace folder (this effectively means you can’t have a www.website.com/build URL but I can live with that)
- I did initially use cp to copy the files in STATICFILES accross, however, this resulted in “new” versions of the file being created every time, which led to files being uploaded every single time, even though there was no change. Given Amazon charge for S3 PUTS, this is somewhat sub optimal! Therefore I used rsync to sync the files accross ensuring only those files which have changed since the last build are updated.
- The same logic explains the reason for using jekyll –incremental.
- The use of the –acl public-read was driven by the fact that if not specified, I discovered the files were not accessible and I was getting a lot of permission denied errors when accessing the pages.
Troubleshooting
I found using the Console Output on the Build report invaluable for working out what was going right - and wrong - when setting up this workflow.